
My main question is about /run/user/1000:
- Should I avoid touching it?
- Could I delete it?
- Is there something wrong with it?
Background: I’m fairly new to Linux and just getting used to it.
I use fsearch to quickly find files (because my filenaming convention helps me to get nearly everything in mere seconds). Yesterday I decided to let it index from root and lower instead of just my home folder.
Then I got a lot of duplicate files. For example in subfolders relating to my mp3 player I even discovered my whole NextCloud ‘drive’ is there again: /run/user/1000/doc/by-app/org.strawberrymusicplayer.strawberry/51b78f5c/N
Searching: Looking for answers I read these, but couldnt make sense of it.
- https://unix.stackexchange.com/questions/162900/what-is-this-folder-run-user-1000
- https://forums.linuxmint.com/viewtopic.php?t=412850 So if its a bug with flatpaks I’m inclined to delete a certain db at ~/.local/share/flatpak/db
Puzzled:
- Is this folder some RAM drive so my disk doesnt show anything strange? Because this folder doesnt even show up at the root level.
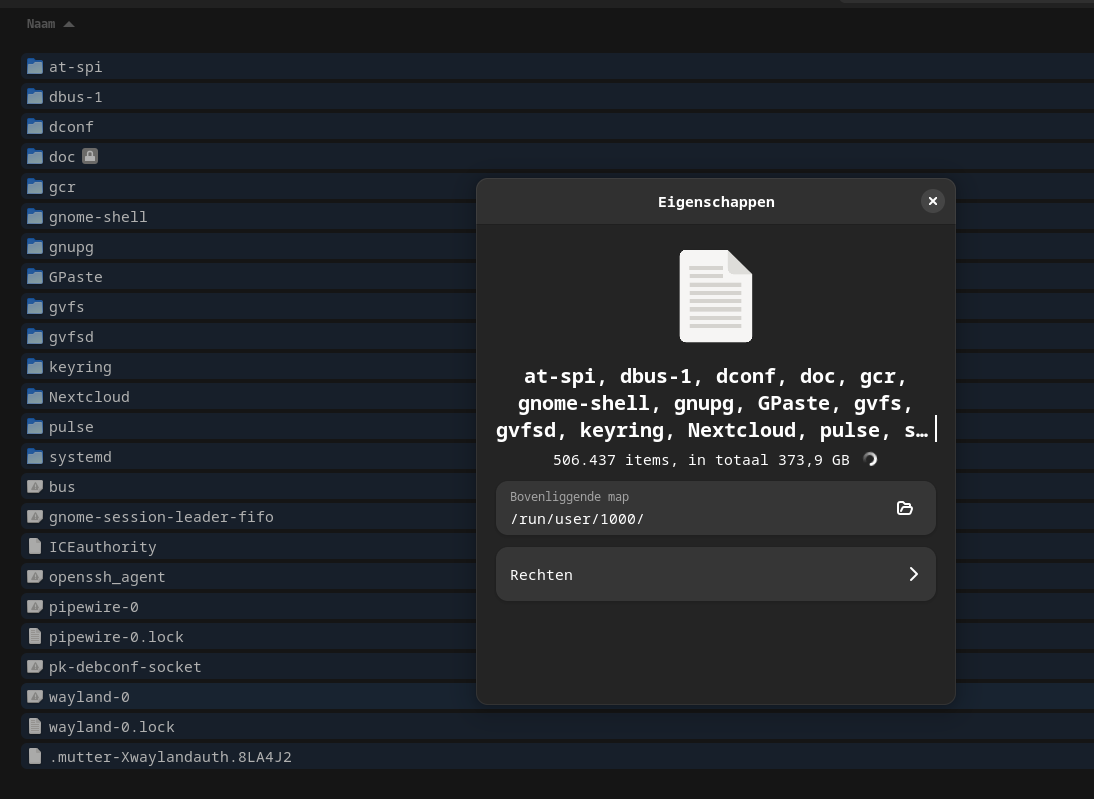
- Are these even real? Because the size of it (aprox 370 GB) is even bigger then my disksize (screenshot).
Any tips about course of (in)action appreciated.
You must log in or register to comment.
Never touch anything in /run directory.
Thanks! And I will remove it from my search index to restrain from “decluttering”. 👌👍
Don’t “declutter” manually. Use your package manager.
I learned a lot in these comments but in this specific context:
- a flatpak app uses a base directory (mp3 player).
- I set it to my NextCloud folder.
- Now run/usr/1000 is “filled” with all my thousands of pdf from personal archive, several times per file (because multiple flatpaks).
These don’t need decluttering I learned, but aren’t managed by package managers either.
Flatpak is itself a file manager.
That duplicate of your folder in /run is due to filesystem links (or more likely a fuse mount, I’ve never actually looked into how flatpak works). But either way, they aren’t copies of the data.
Don’t use flatpak. It encourages dependency hell and ruins validation.
The search index isn’t managed by you package manager, is it?
I’d say a good rule of thumb for a beginner is not to touch anything outside of their own home directory. Modifying or deleting files in other locations is an easy way to break your system.
Honestly as a power user for 10 years I very, very rarely come across a time it’s a good idea to touch anything outside the home directory.
/etc/fstab if you need to setup a new disk
Sound advice, thnx
https://serverfault.com/questions/24523/meaning-of-directories-on-unix-and-unix-like-systems
- /bin - Binaries.
- /boot - Files required for booting.
- /dev - Device files.
- /etc - Et cetera. The name is inherited from the earliest Unixes, which is when it became the spot to put config-files.
- /home - Where home directories are kept.
- /lib - Where code libraries are kept.
- /media - A more modern directory, but where removable media gets mounted.
- /mnt - Where temporary file-systems are mounted.
- /opt - Where optional add-on software is installed. This is discrete from /usr/local/ for reasons I’ll get to later.
- /run - Where runtime variable data is kept.
- /sbin - Where super-binaries are stored. These usually only work with root.
- /srv - Stands for “serve”. This directory is intended for static files that are served out. /srv/http would be for static websites, /srv/ftp for an FTP server.
- /tmp - Where temporary files may be stored.
- /usr - Another directory inherited from the Unixes of old, it stands for “UNIX System Resources”. It does not stand for “user” (see the Debian Wiki). This directory should be sharable between hosts, and can be NFS mounted to multiple hosts safely. It can be mounted read-only safely.
- /var - Another directory inherited from the Unixes of old, it stands for “variable”. This is where system data that varies may be stored. Such things as spool and cache directories may be located here. If a program needs to write to the local file-system and isn’t serving that data to someone directly, it’ll go here.
Thanks, this doesn’t say anything tho about 2 levels deep in bullet 10. But I get anything in run/user/1000 serves the same purpose.
In this case, yes anything under /run should not be considered as normal files.
The above is accurate, and can be considered accurate for any directory below or at well.
Per /run, it’s also mounted in memory, so trying to “declutter” it won’t get you anywhere and things will return on reboot.
/run contains all sorts of virtual stuff, it doesn’t persist over a reboot,
I would advise against deleting anything in it as those files are used by programs running as whether user has the ID of 1000 (most likely you)
it contains things such as sockets and lock files so that programs can interact with each other
Only thing i saw here are general answers. /run/user/1000 resp. $XDG_RUNTIME_DIR is a tmpfs (somt. like a ramdisk) created by PAM (pluggable authentication module) on login, 1000 being your user id. It is more restricted in security and size than cache and should be used for small files where quick access or security matters. A common example are sockets.
You can delete it, it will just be regenerated next log in, but your very session will run into trouble, you should log out after (if you don’t just get booted out, that is).
And yeah, like others said; this is not Windows, you don’t have to, and shouldn’t, clean up anything outside your home dir.
Something to realise when starting with Linux is that everything is a ‘file’. Sockets, processes, input, output etc. That’s very different from Windows and part of why scripting on Linux is so powerful. You can interact with anything.
So some directories are filled with things that aren’t necessarily files but look like it. Someone else posted a whole list, just realise that under those directories/paths shouldn’t be messed with unless you know what it’s for.
Generally when you’re getting used to Linux, /home/$user (aka ~) is where you put personal things. The rest is managed by OS and applications, don’t worry about it.
Edit: spelling@joeldebruijn@lemmy.ml the /run/user/1000 directory is an in-memory file system of a fairly small size. The operating system creates it for you to store certain things that are for your user account only. The permission settings on this directory forbid any other user on the system (except for “root”) to see what is inside. This makes it safe to store secret information that only you should know.
One typical example of something stored in this directory would be your plain text (unencrypted) password database if you use a password manager. No other user but you (and “root”) can see it, and it is in-memory only so it is not accidentally copied to your persistent memory (HDD or SSD disk drive) where it might be removed and read by hackers if someone steals your computer from you. At the same time, any program running on the system that was launched by you and only you has access to your passwords so you don’t need to remember passwords for everything. (Actually it is a socket to a server containing your unencrypted password database in memory, it is probably not actually a file in that directory.)
Other things that go in this /run/user/1000 directory are socket connections to the desktop bus (allows for things like copy-and-paste or drag-and-drop to work between programs), socket connections to your audio mixer (allows you do things like to listen to music and do video chat at the same time), and a record of what external media devices you have connected to the computer which you are using via GVFS, and so on.
Also, the number 1000 is your user ID number assigned to you by the operating system. If you create other accounts, they will have ID 1001, 1002, and so on, and each of them will have a directory with that number created in the /run/user directory for them when they login.
When I let fsearch index from root, it counted 1.9 million files, which baffled me a lot. Before knowing the things in this thread. A typical windows install can have 50k ~ 100k files, but … 2 million I thought it was insane.
But in this context its something like if LibreOffice Calc had an API and upon start it registers a filesystem with a ‘folder’ for every worksheet and a ‘file’ named A1, A2, B1 … for every cell. Not real I know but a novice way of understanding.
Something like that indeed.
Every active network connection, every process, every piece of hardware and others are in your file system.
Then there’s also the possibility for linking to a file and links take up no space, but can show up like files.
You can use a command like ‘stat’ to get more information about a file (or directory).
Then I got a lot of duplicate files. For example in subfolders relating to my mp3 player I even discovered my whole NextCloud ‘drive’ is there again: /run/user/1000/doc/by-app/org.strawberrymusicplayer.strawberry/51b78f5c/N
In Linux a file can show up several times in the filesystem without being duplicated. Symbolic links and hard links will cause this to happen, and they’re a normal part of organizing the filesystem. Just because you see a file in several places, that doesn’t mean disk space is wasted with duplicates. There may be only one physical copy of the file, appearing in multiple places. With hard links you need to be especially careful about deleting, since you’ll think you’re deleting one of several duplicates but you’ll in fact delete the only copy of the file.
Don’t delete it. It’s an area of the filesystem where the current user session data is kept. This includes things like sockets to communicate with other session components and lock files. It’s usually hosted on a ram disk so takes up no space in the system and goes away when you shutdown your machine.
Or it comes back the same way but doesn’t pose a problem either?
Files in /run will be (re)created (and removed) at runtime if/when needed by programs that need them. They pose no problems and don’t persist between reboots.
You’re going to want to look up things like symlinks, hard links, fuse filesystems, and bind mounts among other concepts. Your “whole directory” and other duplicates are artifacts of how the filesystem and process management works, and simply running fsearch or find over them is going to be confusing if you don’t know what you’re looking at.
One Unix concept that carries over to Linux is that everything is a file. Your shared memory space, process data, device driver interfaces, etc, all of it is accessible somewhere in the same virtual filesystem tree as the actual files.
Because of this, there’s very little reason to have the whole filesystem indexed from root. If you’re worried about space usage, you want to work with packages through the package manager. If you’re worried about system integrity, you’ll want package validators.
Thanks, gives me direction in which way to do research.
Other people already answered the question, I just want to say that this question was incredibly well asked.
Thanks, definitly positif first time experience with posting also.
Do not touch that as you will break things. It varies per setup on how it is used but everything /run is virtual
The most important thing to realize about the “file system” in Linux is it does a lot more than just persist your documents and app data. You shouldn’t index your root directory because almost everything other than your home directory is some kind of Linux distro/application-specific directory that is often not a normal directory stored on a storage device. If you run the
mountcommand with no arguments, every line of output is a separate file system, mounted at some specific directory of the current “mount namespace”. Kinda confusing, but every process in Linux has a mount namespace that has a list of mounted file systems, often that namespace is shared between many/most processes, such as your terminal shell. Most of the file systems will be virtual i.e. not representing anything in storage. For example sysfs (always mounted at /sys), proc (always mounted at /proc), devtmpfs (mounted at /dev), etc. are all completely virtual and are ways for system services and applications to access state and devices exposed by the Linux kernel. They should never be indexed, treated as normal files, or modified by the user.That’s probably even more confusing, sorry. But the gist of it is, the only directory on your system you can really count on actually being stored on disk and always available to you is your home directory. Basically everything else exists as an implementation detail of the operating system and software applications.
If I were you, I’d stick to only indexing your user home directory. Indexing /usr or /tmp or /etc or whatever is like indexing C:\Windows and C:\Program Files, except even weirder since at least on Windows those are actually files stored on disk whereas in Linux they may not even be actual files (although most of them in /usr and /etc are actual files on disk).
Ow … this … just realise its my Windows “legacy-skills” to unlearn …
Although its indeed more confusing it does explain rather well I cant just “port” my habits from Windows to Linux (Debian Gnome in my case).
Also it gave me hints for more research. Thanks!
You may also encounter some contradictory information out there too. For example, I said don’t modify stuff outside of your user home directory, but some people will advise to modify stuff in /etc. Although I would never do this on a desktop distro (usually /etc is set up the way the distro maintainers want it, and anything you need to modify will have another more user-friendly way to modify it), especially one where you’re mostly just trying to run desktop applications. It might make sense to modify stuff in /etc on a server installation since that’s where a lot of configuration for different daemon processes (i.e. system services but also server applications) and even software libraries goes.
That’s one of the good and bad things about linux. There is some information about all this stuff on the internet if you can find it, but it is also an information overload and you’re basically learning about the internals of the operating system with all the associated complexity. That’s one thing that threw me off about linux initially (I started getting into this stuff only a couple years ago), almost everything you learn about linux is basically an implementation detail. There are Windows equivalents to most things in linux, but when you use Windows as a desktop user you don’t really think about them unless you’re developing an application using Windows-specific APIs.
Windows has things like COM (linux equivalent is gobject and dbus), Services (linux equivalent is systemd services), Win32 API (this is a million things in Linux like glibc and a bunch of other system libraries, just check out how many files are in /usr/lib or /usr/lib64), Registry (dconf/gsettings) and so on.
There’s also unfortunately no real clean break between “stuff anyone should know” and “stuff programmers and linux distro developers should know”. A lot messier than something like iOS or Android where if you’re a normal user you basically don’t see the OS implementation or hints of it at all.
Trying to hide the implementation details is also why the GNOME Files app shows you some documents folders on the left but makes it more difficult to view the root directory or even the current file path. Which was very frustrating and confusing for me, coming from Windows.
There is a simple trick, as a basic user, do not ever run your (gnome) file explorer as root and if a permission error (requiring “escalation”) pops up you shoud double check what you are doing.
I think most graphical file mangers also keep most of the weird/important/system folders away from user and you have to directly navigate to them.
I think others have answered what the folder should do.
FSearch is great, but I wouldn’t index the entire file system. There isn’t much point in indexing things you won’t be using such as all the system files and the representations of hardware processes. It’s a bit like on Windows indexing c:\windows - you just don’t need all that clogging up your search results. But the Linux filesystem encompasses much more so you’d get even more stuff.
On my system I index my home folder (where all your own files will be kept) and my mount points (for me a series of drives I mount under /mnt/). You could also index /media (or variants) as that is where USB drives, and CDs etc would mount to - but I don’t tend to index USB sticks etc.
I can see circumstances where you might want to index other locations depending on how you use fsearch and Linux, but I think for most users it’d just be unnecessary indexing and results.
Edit: I saw someone else mention /etc too. That can be useful if you want to find system config files. They also mentioned /usr/share/docs which contains a lot of the Linux manual/distro docs amongst others. If you want to access that then it’s not a bad idea to index it, although most people are online all the time now on multiple devices so it may be a bit redundant for most users day to day; I tend to just search online documentation.
Thanks everybody, I learned a ton these 2 days. Like a ’ jump’ in understanding. Not only the specific answer to my concrete question but also on a conceptual level as well.
The thing that makes Linux next level for me now is the extra ‘abstraction layer’.
Thing is, for me, digital files always were as tangible as the analog object they represent. A digital document is as ‘real’ as a paper document. An email as real as a letter. But untill now files where ‘real’ digital artefacts. And thats … a bit different with ‘virtual’ files, sort of.
Anyway, new concepts to explore which is great!
Nice that you are using FSearch :) I would put more excludes in it when you really want to index / In fact, apart from /home I would not index anything else than /etc /usr/share/doc and maybe /var/run/media or /media (depending on which Linux distribution you are using, for example Arch Linux will use /var/run/media and Ubuntu will use /media for removable devices).






{kind=link}