

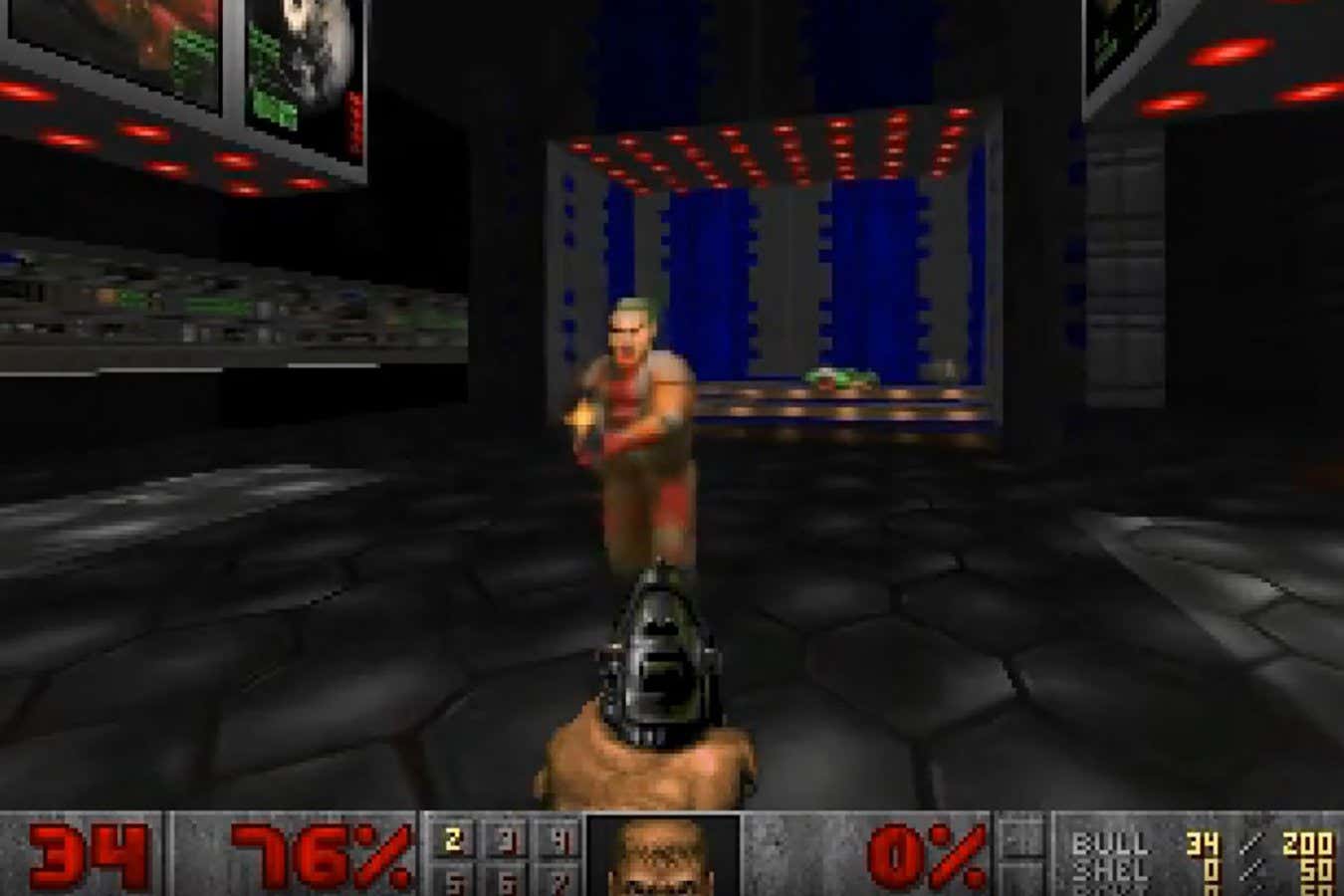
The model, called GameNGen, was made by Dani Valevski at Google Research and his colleagues, who declined to speak to New Scientist. According to their paper on the research, the AI can be played for up to 20 seconds while retaining all the features of the original, such as scores, ammunition levels and map layouts. Players can attack enemies, open doors and interact with the environment as usual.
After this period, the model begins to run out of memory and the illusion falls apart.
Is it though? We can show an AI thousands of hours of something and it can simulate it almost perfectly. All the game mechanics work! It even makes you collect keys and stock up on ammo. For a stable diffusion model that’s pretty profound emergent behavior.
I feel like you’re kidding yourself if you don’t think this has real world applications. This is the kind breakthrough we need for self-driving: the ability to simulate what would happen in real life given a precise current state and a set of fictional inputs.
Doom is a low-graphics game, so it’s definitely easier to simulate, but this method could make the next generation of niche “VidGen” models extremely accurate.
Can’t wait for your self-driving car to go out of memory mid ride.
I’m not convinced. The ammo seems to go up and down on a whim, as does the health
Because “AI” isn’t actually “artificial intelligence.” It’s the marketing term that seems to have been adapted by every corporation to describe “LLMs…” which are more like extra fancy power guzzling parrots.
Its why the best cases for them are mimicking things brainlessly, like voice cloning for celebrity impressions… but that doesn’t mean it can act or comprehend emotion, or know how many fingers a hand should have and why they constantly hallucinate contextless bullshit… because just like a parrot doesn’t actually know any meaning of what it is saying when it goes “POLLY WANT A CRACKER…” it just knows the tall thing will give it a treat if it makes this specific squawk with its beak.
Honestly I thinkyour self driving example is something this could be really cool for. If the generation can exceed real time (I.e. 20 secs of future image prediction can happen in under 20 secs) then you can preemptively react with the self driving model and cache the results.
If the compute costs can be managed maybe even run multiple models against each other to develop an array likely branch predictions (you know what I turned left)
Its even cooler that player input helps predict the next image.