
- cross-posted to:
- technology@lemmy.world
- cross-posted to:
- technology@lemmy.world
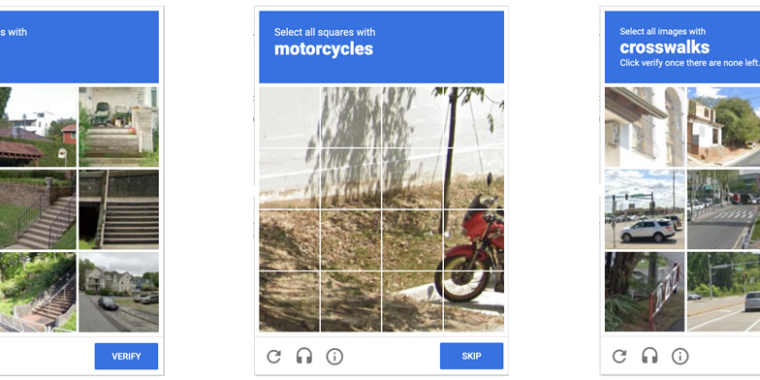
Anyone who has been surfing the web for a while is probably used to clicking through a CAPTCHA grid of street images, identifying everyday objects to prove that they’re a human and not an automated bot. Now, though, new research claims that locally run bots using specially trained image-recognition models can match human-level performance in this style of CAPTCHA, achieving a 100 percent success rate despite being decidedly not human.
ETH Zurich PhD student Andreas Plesner and his colleagues’ new research, available as a pre-print paper, focuses on Google’s ReCAPTCHA v2, which challenges users to identify which street images in a grid contain items like bicycles, crosswalks, mountains, stairs, or traffic lights. Google began phasing that system out years ago in favor of an “invisible” reCAPTCHA v3 that analyzes user interactions rather than offering an explicit challenge.
Despite this, the older reCAPTCHA v2 is still used by millions of websites. And even sites that use the updated reCAPTCHA v3 will sometimes use reCAPTCHA v2 as a fallback when the updated system gives a user a low “human” confidence rating.
No you’re wrong, because the sites that embed those captchas on their page are not doing that to help good.
Yes, they are getting something productive out of the human labor that would be done anyways. Trust me as a web developer, and web scraper, some kind of captcha is necessary for many free services to be useful/economically viable. The core of a good captcha is just making it marginally more expensive for the scraper/bot than it is for you.
The sites don’t create the captcha, you yourself just said it was embedded there.
They embed for a reason… And the captchas wouldn’t exist if they weren’t embedded anywhere
Finitebanjo is right. Yes they are used to fight spam and bots but they way they do it us is picked intentionally to train ai.
https://medium.com/@yennhi95zz/how-google-trains-ai-with-your-help-through-captcha-876cb4eb4d01
Also from the Wikipedia article “Google profits from reCAPTCHA users as free workers to improve its AI research.” https://en.m.wikipedia.org/wiki/ReCAPTCHA
Yes like I said, the challenges were picked to be useful. But some form of challenge would’ve been chosen regardless.