That’s why you use unit test and integration test.
Good start, but not even close to being enough. What if code introduces UB? Unless you specifically look for that, and nobody does, neither unit nor on-target tests will find it. What if it’s drastically ineffective? What if there are weird and unusual corner cases?
Now you spend more time looking for all of that and designing tests that you didn’t need to do if you had proper practices from the beginning.
It would probably a nice idea to do some kind of turing test, a put a blind test to distinguish the AI written part of some code, and see how precisely people can tell it apart.
But that’s worse! You do realise how that’s worse, right? You lose all the external ways to validate the code, now you have to treat all the code as malicious.
For instance, to seek for specific functions in C# extensive libraries.
And spend twice as much time trying to understand why can’t you find a function that your LLM just invented with absolute certainty of a fancy autocomplete. And if that’s an easy task for you, well, then why do you need this middle layer of randomness. I can’t think of a reason why not to search in the documentation instead of introducing this weird game of “will it lie to me”
Also I don’t see how you will take more that 5 second to verify that a given function does not exist. It has happen to me, llm suggesting unexisting function. And searching by function name in the docs is instantaneous.
I you don’t want to use it don’t. I have been more than a year doing so and I haven’t run into any of those catastrophic issues. It’s just a tool like many others I use for coding. Not even the most important, for instance I think LSP was a greater improvement on my coding efficiency.
It’s like using neovim. Some people would post me a list of all the things that can go bad for making a Frankenstein IDE in a ancient text editor. But if it works for me, it works for me.
And there is enormous amount of safeguards, tricks, practices and tools we come up with to combat it. All of those are categorically unavailable to an autocomplete tool, or a tool who exclusively uses autocomplete tool to code.
Also I don’t see how you will take more that 5 second to verify that a given function does not exist. It has happen to me, llm suggesting unexisting function. And searching by function name in the docs is instantaneous.
Which means you can work with documentation. Which means you really, really don’t need the middle layer, like, at all.
I haven’t run into any of those catastrophic issues.
Glad you didn’t, but also, I’ve reviewed enough generated code to know that a lot of the time people think they’re OK, when in reality they just introduced an esoteric memory leak in a critical section. People who didn’t do it by themselves, but did it because LLM told them to.
I you don’t want to use it don’t.
It’s not about me. It’s about other people introducing shit into our collective lives, making it worse.
You can actually apply those tools and procedures to automatically generated code, exactly the same as in any other piece of code. I don’t see the impediment here…
You must be able to understand that searching by name is not the same as searching by definition, nothing more to add here…
Why would you care of the shit code submitted to you is bad because it was generated with AI, because it was copied from SO, or if it’s brand new shit code written by someone. If it’s bad is bad. And bad code have existed since forever. Once again, I don’t see the impact of AI here. If someone is unable to find that a particular generated piece of code have issues, I don’t see how magically is going to be able to see the issue in copypasted code or in code written by themselves. If they don’t notice they don’t, no matter the source.
I will go back to the Turing test. If you don’t even know if the bad code was generated, copied or just written by hand, how are you even able to tell that AI is the issue?
The things I am talking about are applied to the development process before you start writing code. Rules from NASA’s the power of 10, MISRA, ISO-26262, DO-178C, and so on, as well as the general experience and understanding of the data flow or memory management. Stuff like that you fundamentally can’t apply to a system that takes random pieces of text from the Internet and puts it into a string until it looks like something.
There is an enormous gray zone between so called good code (which might actually not exist), and bad code that doesn’t work and has obvious problems from the beginning. That’s the most dangerous part of it, when your code looks like something that can pass your “Turing test”, that’s where the most insidious parts get introduced, and since you completely removed that planning part and all the written in blood rules it introduced, and you eliminated experience element, you basically have to treat all the code as the most malicious parts of it, and since it’s impossible, you just dropped your standards to the ground.
It’s like pouring sugar into concrete. When there is a lot of it, it’s obvious and concrete will never set. When there is just enough of it, it will, but structurally it will be undetectably weaker, and you have no idea when it will crack.
Not every program is written for spacecraft, and does not net the critique level of safety and efficiency as the code for the Apollo program.
I don’t even know. If memory issues are your issue then using any program with safe memory embedded into it is the way to go. As most things are actually made right now. Unless you are working in legacy applications most programmers would never actually run into that many memory issues nowadays. Not that most programmers would even properly understand memory. Do you think the typical JavaScript bootcamp rookie can even differentiate when something is stored in the stack or the heap?
You are talking like every human made code have Linux Kernel levels of quality, and that’s not the case, not by far.
And it doesn’t need to. Not all computer programs are critically important, people be coding in lua for pico-8 in a gamejam, what’s the issue for them to use AI tools for assistance?
And AI have not existed before a couple of years and our critically important programs are everywhere. Written by smart humans who are making mistakes all the time. I still do not see the anti-AI point here.
Also programming is not concrete, and AI is not sugar. If you use AI to create a fast tree structure and it works fine, it’s not going to poison anything. It’s probably be just the same function that the programmer would have written, just faster.
Also, not addressing the fact thar if AI is bad because it’s just copying, then it’s the same as the most common programming texhnique, copying code from Stack Overflow.
I have a genuine question, how many programmers do you think that code in the way you just described?

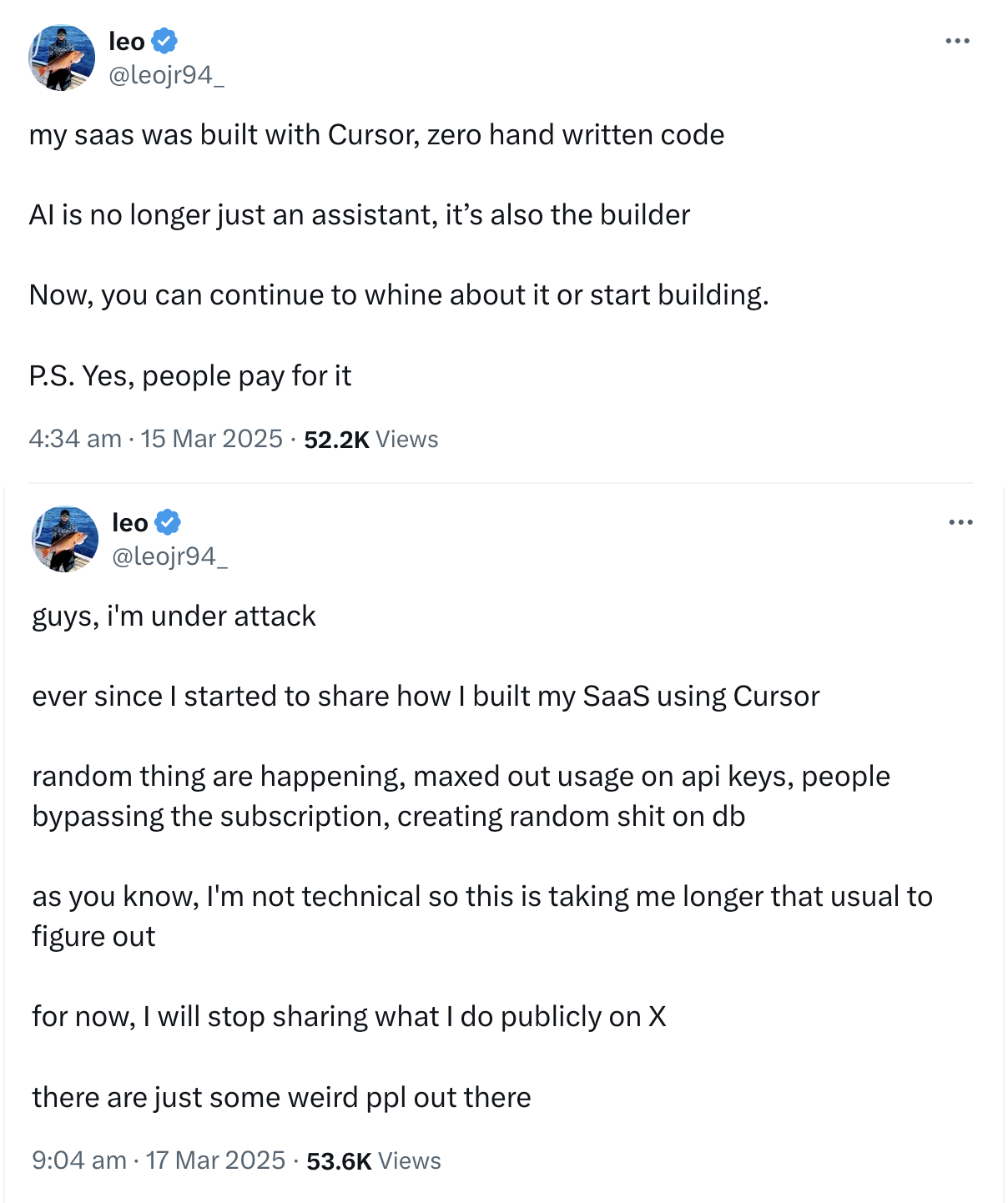{kind=link}
Good start, but not even close to being enough. What if code introduces UB? Unless you specifically look for that, and nobody does, neither unit nor on-target tests will find it. What if it’s drastically ineffective? What if there are weird and unusual corner cases?
Now you spend more time looking for all of that and designing tests that you didn’t need to do if you had proper practices from the beginning.
But that’s worse! You do realise how that’s worse, right? You lose all the external ways to validate the code, now you have to treat all the code as malicious.
And spend twice as much time trying to understand why can’t you find a function that your LLM just invented with absolute certainty of a fancy autocomplete. And if that’s an easy task for you, well, then why do you need this middle layer of randomness. I can’t think of a reason why not to search in the documentation instead of introducing this weird game of “will it lie to me”
Any human written code can and will introduce UB.
Also I don’t see how you will take more that 5 second to verify that a given function does not exist. It has happen to me, llm suggesting unexisting function. And searching by function name in the docs is instantaneous.
I you don’t want to use it don’t. I have been more than a year doing so and I haven’t run into any of those catastrophic issues. It’s just a tool like many others I use for coding. Not even the most important, for instance I think LSP was a greater improvement on my coding efficiency.
It’s like using neovim. Some people would post me a list of all the things that can go bad for making a Frankenstein IDE in a ancient text editor. But if it works for me, it works for me.
And there is enormous amount of safeguards, tricks, practices and tools we come up with to combat it. All of those are categorically unavailable to an autocomplete tool, or a tool who exclusively uses autocomplete tool to code.
Which means you can work with documentation. Which means you really, really don’t need the middle layer, like, at all.
Glad you didn’t, but also, I’ve reviewed enough generated code to know that a lot of the time people think they’re OK, when in reality they just introduced an esoteric memory leak in a critical section. People who didn’t do it by themselves, but did it because LLM told them to.
It’s not about me. It’s about other people introducing shit into our collective lives, making it worse.
You can actually apply those tools and procedures to automatically generated code, exactly the same as in any other piece of code. I don’t see the impediment here…
You must be able to understand that searching by name is not the same as searching by definition, nothing more to add here…
Why would you care of the shit code submitted to you is bad because it was generated with AI, because it was copied from SO, or if it’s brand new shit code written by someone. If it’s bad is bad. And bad code have existed since forever. Once again, I don’t see the impact of AI here. If someone is unable to find that a particular generated piece of code have issues, I don’t see how magically is going to be able to see the issue in copypasted code or in code written by themselves. If they don’t notice they don’t, no matter the source.
I will go back to the Turing test. If you don’t even know if the bad code was generated, copied or just written by hand, how are you even able to tell that AI is the issue?
The things I am talking about are applied to the development process before you start writing code. Rules from NASA’s the power of 10, MISRA, ISO-26262, DO-178C, and so on, as well as the general experience and understanding of the data flow or memory management. Stuff like that you fundamentally can’t apply to a system that takes random pieces of text from the Internet and puts it into a string until it looks like something.
There is an enormous gray zone between so called good code (which might actually not exist), and bad code that doesn’t work and has obvious problems from the beginning. That’s the most dangerous part of it, when your code looks like something that can pass your “Turing test”, that’s where the most insidious parts get introduced, and since you completely removed that planning part and all the written in blood rules it introduced, and you eliminated experience element, you basically have to treat all the code as the most malicious parts of it, and since it’s impossible, you just dropped your standards to the ground.
It’s like pouring sugar into concrete. When there is a lot of it, it’s obvious and concrete will never set. When there is just enough of it, it will, but structurally it will be undetectably weaker, and you have no idea when it will crack.
Not every program is written for spacecraft, and does not net the critique level of safety and efficiency as the code for the Apollo program.
I don’t even know. If memory issues are your issue then using any program with safe memory embedded into it is the way to go. As most things are actually made right now. Unless you are working in legacy applications most programmers would never actually run into that many memory issues nowadays. Not that most programmers would even properly understand memory. Do you think the typical JavaScript bootcamp rookie can even differentiate when something is stored in the stack or the heap?
You are talking like every human made code have Linux Kernel levels of quality, and that’s not the case, not by far.
And it doesn’t need to. Not all computer programs are critically important, people be coding in lua for pico-8 in a gamejam, what’s the issue for them to use AI tools for assistance?
And AI have not existed before a couple of years and our critically important programs are everywhere. Written by smart humans who are making mistakes all the time. I still do not see the anti-AI point here.
Also programming is not concrete, and AI is not sugar. If you use AI to create a fast tree structure and it works fine, it’s not going to poison anything. It’s probably be just the same function that the programmer would have written, just faster.
Also, not addressing the fact thar if AI is bad because it’s just copying, then it’s the same as the most common programming texhnique, copying code from Stack Overflow.
I have a genuine question, how many programmers do you think that code in the way you just described?