Assuming AI Overview does not cache results, they would be generated at search-time for each user and “search-event” independently. Even recreating the same prompt would not guarantee a similar AI Overview, so there’s no way to confirm.
Edit: See my comment below for what I actually meant to say
My bad, I wasn’t precise enough with what I wanted to say. Of course you can confirm (with astronomically high likelihood) that a screenshot of AI Overview is genuine if you get the same result with the same prompt.
What you can’t really do is prove the negative. If someone gets an output then replicating their prompt won’t necessarily give you the same output, for a multitude of reasons. e.g. it might take all other things Google knows about you into account, Google might have tweaked something in the last few minutes, the stochasticity of the model is leading to a different output, etc.
Also funny you bring up image generation, where this actually works too in some cases. For example they used the same prompt with multiple different seeds and if there’s a cluster of very similar output images, you can surmise that an image looking very close to that was in the training set.
I do that with LLM a fair bit. If just using GPTs website for something that should be simple, I often prompt the same thing several times and choose the best iteration as a base.


{kind=link}
Assuming AI Overview does not cache results, they would be generated at search-time for each user and “search-event” independently. Even recreating the same prompt would not guarantee a similar AI Overview,
so there’s no way to confirm.Edit: See my comment below for what I actually meant to say
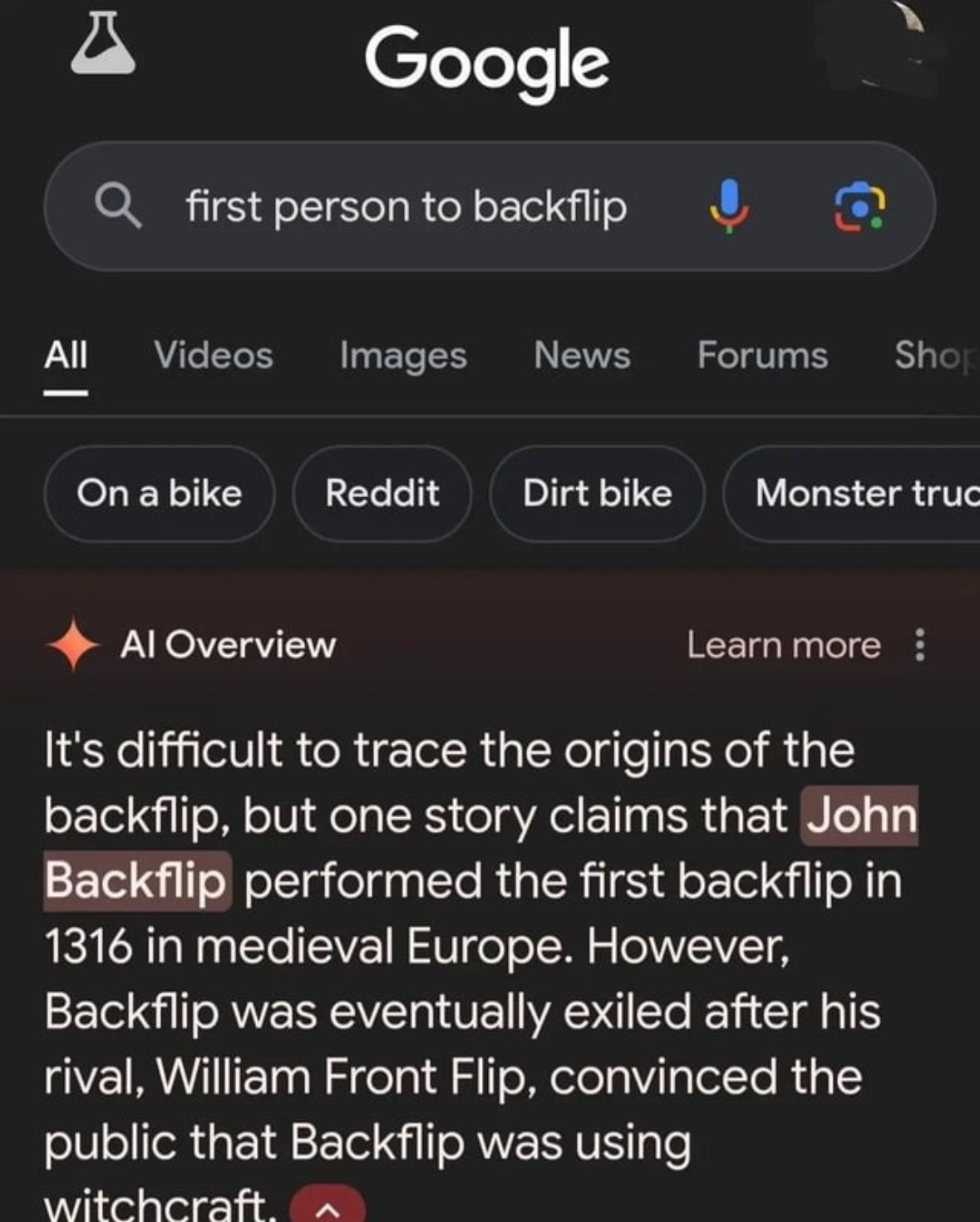
Multiple people in this thread, including myself, have the exact same tiktok meme quote as results for that prompt.
“AI Overciew” is not the same as randomized image generation.
My bad, I wasn’t precise enough with what I wanted to say. Of course you can confirm (with astronomically high likelihood) that a screenshot of AI Overview is genuine if you get the same result with the same prompt.
What you can’t really do is prove the negative. If someone gets an output then replicating their prompt won’t necessarily give you the same output, for a multitude of reasons. e.g. it might take all other things Google knows about you into account, Google might have tweaked something in the last few minutes, the stochasticity of the model is leading to a different output, etc.
Also funny you bring up image generation, where this actually works too in some cases. For example they used the same prompt with multiple different seeds and if there’s a cluster of very similar output images, you can surmise that an image looking very close to that was in the training set.
The best tools are inconsistent!
I do that with LLM a fair bit. If just using GPTs website for something that should be simple, I often prompt the same thing several times and choose the best iteration as a base.